Is Generative AI all hype?




Late last year, we spent a few weeks with the Canopy Study team. Over that period of time, we got a great crash course on Large Language Models (LLMs), Transformers and more. We ended up leading a A$1.1M Pre-Seed round in the business. Since then we followed the space closely and kept a pulse on the latest innovations in both text-based and multimodal Generative AI.
Over the last couple of months, the Generative AI space has been hot. Jasper raised US$125M in their Series A and Stability AI raised $101M for their Seed round both of which are mind-blowing in a recessionary environment where funding is muted in every other sector.

In this article, we’ll explore the world of LLMs, prompt engineering and whether this is all just hype. Let’s get into it!
Neural networks were inspired by the human brain. However, when they were initially created, they had no memory. They weren’t able to use past decisions to inform new ones which places them at a huge disadvantage.
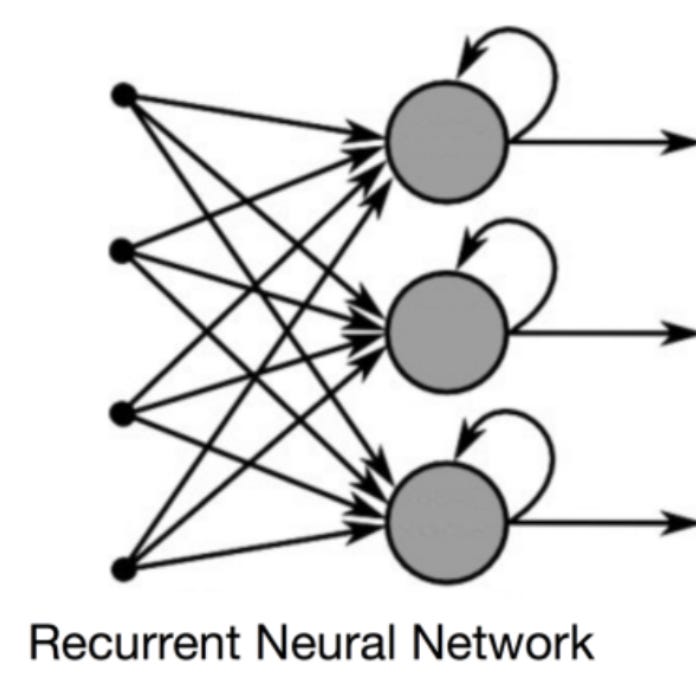
This was solved by Recurrent Neural Networks (RNNs). RNNs are able to remember things about inputs which allows them to be very precise in making sequential forecasts. RNNs have been applied to speech recognition, financial forecasting, translations and more.
Memory is a powerful thing. As humans, we rely on both short and long-term memory to inform our future decisions. Our cognitive biases may lead us to put more weight on recent events when making a decision, which in turn may make us more or less likely to follow through with that decision.
RNNs, are heavily biased towards short-term context. They largely rely on a small subset of sequential data to generate the next output. However, to increase the accuracy of the output and to ensure the RNN is using all the information available, it needs a little help.
This help comes in the form of Long Short Term Memory networks (LSTMs) which are capable of learning longer-term relationships. LSTMs are able to control the flow of information into a network through three gates. Whilst we can go deep into how these gates work, at a high level, LSTMs determine what information to remember, and what to forget so that a network is only ingesting information that is highly relevant to a sequential prediction. As a result, LSTMs have been able to deliver better performance than standard RNNs.
However, LSTMs still struggle with handling very long sequences. Their memory is still dependent on current and previous input interrelationships with longer-term relationships being forgotten over time. To combat this, attention mechanisms were developed.
This mechanism relies on all available information to generate a prediction, but it uses weights to give certain information more importance than others. This means that models with an attention mechanism aren’t plagued by long-term memory loss.
RNNs and LSTMs are powerful, but their recursive nature makes them very computationally expensive which reduces their ability to be used by the masses.
Transformer models improve upon RNNs by not being recursively architected but similarly rely on an attention mechanism. Rather than needing to process data sequentially during training, Transformers can process data in parallel, which is much faster. This involves handling both the input and output portions of a sequence at the same time.
Transformers ingest inputs differently compared to a standard RNN. Rather than processing words sequentially, whole sentences are processed together. However, the trade-off to processing the data like this is that the positional information for each word is lost and needs to be specifically added back later.
Transformers also handle the attention mechanism in a unique way. They use self-attention to focus and understand the context within a single sequence of information. For example, if we fed the sentence “Liam is incredibly tall and he is a Giraffe”, into a model, we would need to apply weights to each word to understand their significance in relation to each other. I.e., the word ‘incredibly’ is more significant to ‘Liam’ than it is to ‘and’. This process is repeated for all words so that each word gets some context from every word in the sentence.

Transformers repeat this process multiple times to create a Multi-Head attention approach to ensure a high level of accuracy. Also, as previously mentioned, Transformers handle both the input and output in parallel during training. As a result, models can also use a Masked Multi-Head attention approach that hides future words in the sequence of current words. This is necessary so that the model doesn’t create outputs that are based on future outputs (sounds confusing I know!).
So now that we understand how AI models have evolved and why Transformers in their current form exist - it’s clear to see why the stars have aligned for AI to really permeate through society.
Transformers are more robust, create more accurate outputs and are computationally efficient versus RNNs. Moreover, the hardware necessary to deal with these large models has also come a long way with the advent of cloud computing and high-performance GPUs.
Whilst OpenAI and Google DeepMind are certainly leading the charge in creating text-based LLMs, the explosion of new entrants into the scene who are either building their own models in-house or are cloning and improving OpenAI and Google’s work is crazy.
On the multimodal side, it is a lot quieter, however, DALL-E 2 and Stable Diffusion have captured a lot of people’s imaginations with the possibility of AI art and avatars. Meta has also released a Generative AI product that allows users to draw a freehand digital sketch and write a text prompt which is then used to produce an AI-generated image.

We’ve also got a ton of new startups building on top of these open-source models. We’ve already got vertical-specific apps such as Jasper and Copy.ai taking advantage of GPT-3 for marketing copy, Canopy Study making it easier to generate beautiful notes and quizzes, and Lex removing writer’s block.

Given the proliferation of startups in the space already, and with many of them building on top of GPT-3 or another open-source model, what creates differentiation and defensibility amongst each of them?

Prompt writers need to intimately understand what the specific open-source model knows about the world. They need to be able to give the model just enough information and context to figure out the patterns it needs to act upon and provide a coherent output.
Whilst prompt engineering can be as complex as you make it, an example that you can try out is in-context learning. The general framework for in-context learning is to give the model a set of examples (also known as few-shots) within the input to learn a new task.
Example input:
This is a list of activities to do on holiday
In the example prompt, we have the context provided upfront i.e., ‘activities to do on holiday’ and a few examples listed. The last example ‘[Tag: Ocean]’ is left blank with GPT-3 expected to generate a response here.
Once this is run, the output (bolded) I received was:
This is a list of activities to do on holiday
With such a simple prompt, outputs can be hit or miss. Sometimes the outputs mimic the structure of the input given. This is most commonly seen in sentences that follow a similar structure. Even in the example above, the activities suggested by GPT-3 are usually just one word.
For a startup building in this space, heavily investing time into prompt engineering can pay huge dividends later. With a superior product, you can naturally expect people to adopt the tool en masse. This then allows the platform to accumulate and process different types of data which can inform future prompt engineering activities which will hopefully create a better product.
Being able to continually optimise and improve the prompts used can assist with the surprisingly large costs associated with AI use. For GPT-3, the pricing structure is dependent on which model you choose to use and what you wish to do with that model. At most, a developer would pay $0.20 to process 1,000 words through GPT-3’s Davinci model.

Whilst $0.20 isn’t much, imagine you spend a solid chunk of time finetuning and testing the prompts you feed into the model. The costs can add up over time. Moreover, the significant investment made into prompt generation can create a huge cost saving later down the track when you have 1,000s of users on your platform on a daily basis.
Whilst it seems straightforward to continually optimise prompts forever, there is an open concern around model evolution affecting how prompts are written and the type of tasks that can be accomplished. The leap from GPT-2 to GPT-3 was huge. GPT-2 was visibly poor in specialised areas, whereas now GPT-3 can handle more complex tasks. With GPT-4 and other model evolutions, it’s unclear what the jump in quality will look like, or how current startups will need to change their proprietary processes to interact with a higher-quality model.
For the time being, it’s clear that prompt engineering is where a large portion of a Generative AI startup will be able to differentiate its core product from other competitors. However, the open question here is what is the point of diminishing returns? At what level of accuracy will users stop caring about the output and care more about the UX or feature set of the product?
So creating jaw-dropping artwork on Midjourney is cool, but is there really an investment case here?
In all honesty, the cycle of Generative AI funding will come to an end just like it did for instant delivery services and metaverse applications. The seemingly ‘cool’ startups in the space that raise big rounds now on the basis that everyone will be able to generate a fake avatar and fake persona will likely not reach a venture-scale outcome.
Instead, the highest-valued startups will likely be those who are able to stick to a specific niche, accumulate large amounts of data and double down on distribution to create their own flywheel. Rather than trying to be a little bit of everything, the true value in this space can be created by sticking to a single vertical and automating menial tasks that humans are currently doing.
I’ll use Canopy Study’s product as one of the best (unbiased view, I promise!) examples of this at the moment. Being able to create a quiz or flashcards with the click of a button from a single PDF can save a student or teacher a few hours of boring work.
There’s a ton of debate around the ethics of Generative AI (which I haven’t explored), its attractiveness as an investment area and what areas of the world should be influenced by it in the future.
Subscribe to our newsletter for updates delivered directly to your inbox.









%20(1).jpg)
